Homelab K8s Platform (RKE2 + Rancher)
The sovereign Kubernetes platform my AI work runs on — a production-style RKE2 cluster on Proxmox with full GitOps (Argo CD), a high-availability control plane, restore-drilled disaster recovery, Grafana 12 observability, encrypted secrets (SOPS/age), and a self-hosted LLM gateway + local inference layered on top.
Overview
This homelab is the sovereign platform my AI work runs on — a production-style Kubernetes cluster on Proxmox (RKE2 + Rancher) that I build, run, and break myself. It is the substrate: a self-hosted LLM gateway, local inference, and retrieval services all sit on top of it, alongside the usual stateful apps.
Everything is managed as code and reconciled through GitOps (Kustomize + Argo CD) — desired state lives in Git, changes are reviewed and reproducible, and drift becomes visible and correctable. Internal services resolve through split-horizon DNS to stable hostnames instead of NodePorts.
What I care about most here is the boring, load-bearing part: a high-availability control plane (multi-node etcd), disaster recovery that is actually restore-drilled rather than just assumed, encrypted secrets, and scoped access. It is, in the end, infrastructure and operations — but it is the kind you can trust an AI platform to live on.
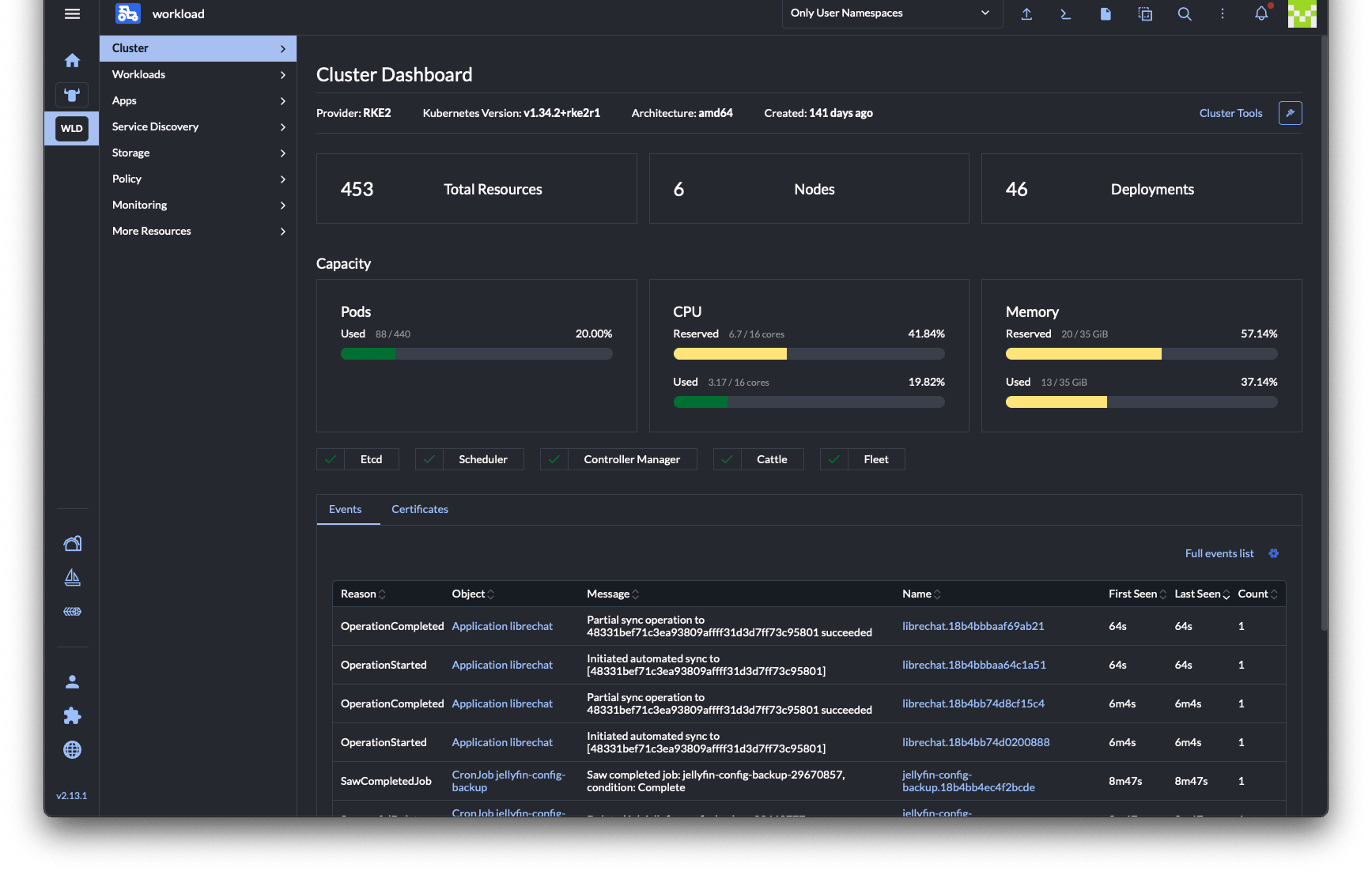
What this demonstrates
- Substrate for AI workloads: a self-hosted LLM gateway (model routing, SSO/RBAC, cost attribution), local inference, and a retrieval (RAG) service on the same platform
- A high-availability control plane (multi-node etcd), with disaster recovery that is restore-drilled, not assumed
- GitOps as the source of truth: Kustomize + Argo CD reconciliation, reviewable diffs, controlled sync, visible drift
- Security hardening by default: OIDC single sign-on (Keycloak), default-deny access, key-only SSH, SOPS/age-encrypted secrets
- Three-layer backup strategy (Proxmox + Velero + etcd), synced off-cluster
- Grafana 12 + Prometheus observability, including AI cost-attribution dashboards
- Storage topology awareness: node-local persistence (
local-path,WaitForFirstConsumer) - Practical Kubernetes operations: deployments, services, ingress, PVCs, probes, rollouts
- MCP server integration for AI-assisted cluster operations
Operational Practices
Reliability & recovery
- Proxmox snapshots before risky changes
- Velero + Kopia for Kubernetes workload backup and restore
- etcd snapshots synced to NAS on schedule
- Documented rollback procedures
Observability
- Grafana 12 dashboards for cluster health and resource usage
- Prometheus metrics across all workloads
- Custom cost attribution dashboards
Security
- Key-only SSH authentication across all nodes
- Scoped kubeconfigs for different access levels
- Secrets encrypted at rest
- MCP servers scoped to read-only at every layer
- OIDC single sign-on (Keycloak) with role-mapped access to platform services